
深度解析 | 故事点估算看这一篇就够了
- 2020-12-26 10:00:00
- 小船哥
- 转贴:
- 微信公众号
- 6084
我在辅导团队对用户故事进行故事点估算的时候,经常会遇到如下问题:
- 用户故事的工作量估算为什么要用故事点,而不是时间?
- 故事点估算为什么要用斐波那契数列?
- 斐波那契数列的数字为什么被改了?
- 为什么要用估算扑克?
- 为什么要有基准故事?
- 怎样确定基准故事?
- 其他故事怎样与基准故事做相对估算?
- ……
1.为什么用故事点而不是时间
在回答这个问题之前,我们先看个例子:韩梅梅和李雷一起去北京奥林匹克森林公园跑步,李雷对韩梅梅说:我们跑南园这条路吧,这大概要花30分钟。
这条路韩梅梅很熟,但是作为一个跑步很慢的人,韩梅梅心里清楚这要花60分钟。所以,韩梅梅告诉李雷,她跑过这条路的,需要花60分钟。
然后他们就争执起来了:30-60-30-60……

他们争执半天没有结果,作为一个热心的旁观者,你可能会劝他们互相妥协一下,就算45分钟吧?但是这样也许是最坏的结果,因为他们虽然有了一个折中的方案,但是这个结果对双方都不太实际:李雷觉得太慢了,而韩梅梅觉得太快了。
所以,他们继续争论:30-60-30-60……
最终,李雷跟韩梅梅说:南园这条路大概5km,我能在30分钟内跑完它。
韩梅梅说:我同意这段路程是5km,但它要花我60分钟。
他们两个都是对的:李雷真的能在30分钟内跑完,韩梅梅也真的需要60分钟。但当他们想为这段路程统一时间估算时,他们发现做不到,因为大家跑步的速率不同。
但是,当他们使用了一个抽象的长度度量单位(km),他们很快就达成了一致。李雷和韩梅梅都同意这段路程是5公里,但是由于他们的速度(相对度量单位)不同,导致他们花费的时间(绝对度量单位)也不同。
例子说完了,很多人这时候可能已经想到了一个公式:距离(km)=速度(km/h)*时间(h),那我为什么要举这个例子呢?难道只是带大家回忆一下小学数学?
其实软件开发中任务的工作量跟跑步的“距离”是非常类似的概念:同一个任务,不管谁来做,它的工作量都是一样的,只不过能力强的人就做得快一点(耗时少);能力弱的人就做得慢一点(耗时多)。与跑步类似,如果我们让多个人就同一个开发任务的耗时达成一致,那是很难的,但是如果我们能有一个描述软件开发工作量的单位(类似表示举例的km),我们可能就能很快达成一致。
而“故事点”就是敏捷开发创造出来的用来表示开发任务工作量的单位,它跟例子中用来表示距离单位的“km”的作用差不多:它能使不同技术水平和工作速率的人在工作量的估算上快速达成一致。当然,敏捷开发的主角是具有不同工作效率的开发人员,而不是例子中不同跑步速度的跑者。

就像这两个跑步的人,两个程序员也许同意一个用户故事是5个故事点(类比例子中的5公里,都是一种抽象度量单位)。高级开发人员可能觉得这很容易,1天(时间)就能完成。初级开发人员可能觉得需要2天才能搞定。但是他们能在5个故事点上快速达成一致,因为把第一个用户故事定成5个故事点是不需要什么依据的(就像不同国家或地区对长度单位的定义可能不同,比如米、寸、英寸等,每个团队对故事点的大小也都可以有自己的标准,只要团队成员都认可即可)。
不过,最重要的是,一旦他们同意第一个故事的工作量是5个点,这两个开发人员就可以对后续估算达成共识。如果高级开发人员认为一个新的用户故事将需要两天(两倍于他估计为5个点的故事),他将评估新的故事为10个点。而初级开发人员也会这样做,当他估算需要4个工作日时(两倍于他估计为5个点的故事),他将评估新的故事为10个点。
2.为什么要用斐波那契数列估算故事点
2.1. 人们无法分辨太小的差异
德国生理学家E.H.韦伯通过对重量差别感觉的研究发现一条定律,即感觉的差别阈限随原来刺激量的变化而变化,而且表现为一定的规律性,刺激的增量(△I)和原来刺激值(I)的比是一个常数(K),用公式表达即K=△I/I,这个常数叫韦伯常数、韦伯分数或韦伯比率。
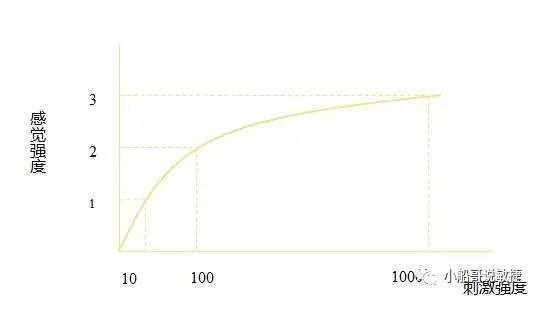
比如:我们大部分人都能分辨出1公斤和2公斤物体,但可能无法分辨出20公斤和21公斤物品。它们同样是相差了1公斤,为什么有的能分辨出来,有的就分辨不出来了呢?这是因为1公斤和2公斤之间的差别是100%,但是20公斤和21公斤之间的差异仅为5%,20公斤和21公斤之间的百分比差异太小了。
2.2. 人们可以分辨出的差异比例
韦伯定律只是告诉了我们可以识别一定百分比差异外的区别,但是这个百分比是多少呢?
- 人们的肚脐是人体总长的黄金分割点
- 大多数门窗的宽长之比也是0.618
- 有些植茎上,两张相邻叶柄的夹角是137°28',这恰好是把圆周分成1:0.618
- 一些名画、雕塑、摄影作品的主题,大多在画面的0.618处
- ……
2.3. 斐波那契数列大致符合了黄金分割比例
斐波那契数列之所以能很好的用于故事点的估算,是因为该数列的数字分布大致符合了黄金分割比例。在这个数列中,1、2、3、5、8、13、21……,前两个值(后一个值比前一个值大100%)之后,后面的每个数字都比前一个数字值大60%左右。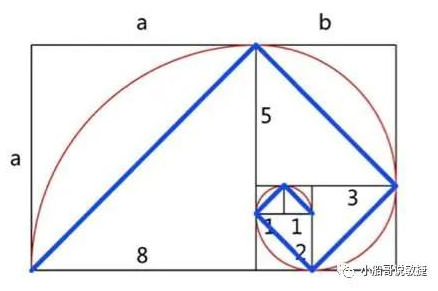
根据韦伯定律,如果我们可以区分两个工作量相差60%的故事,则可以区分其他相同百分比差异的故事。
3. 为什么敏捷估算要使用修正后的斐波那契数列
标准的斐波那契数列是1、2、3、5、8、13、21、34、55……,但是目前绝大多数团队在估算时使用的斐波那契数列是1、2、3、5、8、13、20、40、100……,数列的前面6个数字是一样的,但是从第7个数字开始,就完全不一样了,这是为什么呢?
Mike Cohn曾经在他的文章中提到,早期的估算他都是根据真实的斐波那契数列进行的(1、2、3、5、8、13、21、34、55……)。
这个数列越往后数字越大,也就说明估算越不准确,所以对于21、34、55这样的估算值,很多人都觉得很奇怪:既然已经估不准了,为什么非要使用21,而不将其四舍五入为20或25呢?
于是Mike Cohn就接受了这个建议,在之后的团队辅导及授课中他就开始使用20而不是21了,并且一直持续到了现在。
后来他又尝试使用了40和100这两个数代替了数列的其他值,之所以这么使用,是因为任务的粒度越粗,估算就越不准确,也就越不需要纠结到底是80、90还是100了。
同时,使用40和100也是不违反韦伯定律的,它们分别比之前的数字增加了100%(20 →40)和150%(40 →100)。这比黄金分割比例的61.8%大得多,人们是可以轻松的分辨出这些工作量的区别的。
4. 为什么要使用规划扑克
相信很多人在估算故事点时,都是使用物理或电子的规划扑克进行的,我们为什么要这么做呢?这个问题需要从一个心理学名词“从众效应”说起。4.1. 什么是从众效应
在估算故事点时,当有人提出一个估算,即使你不同意,但当别人都表达赞同时,你还是会随声附和,这就是所谓的“从众效应”: 人们认为如果其他人都赞同某一件事时,那么自己的保留意见则是愚蠢的或是误导性的,他们不想在其他人面前出丑。

- 信息瀑布
- 光环效应
当认知者对一个人的某种特征形成好或坏的印象后,还倾向于推论该人其他方面的特征,本质上属于以偏概全的认知错误。与从众效应一样,光环效应也会导致人们将目光集中到某一个有正面色彩的光环上,从而忽视了实际数据。
4.2. 使用“德尔菲法”降低从众效应的影响
德尔菲法,也称专家调查法,1946 年由美国兰德公司创始实行, 其本质上是一种反馈匿名函询法,其大致流程是在对所要预测的问题征得专家的意见之后,进行整理、归纳、统计,再匿名反馈给各专家,再次征求意见,再集中,再反馈,直至得到一致的意见。
兰德公司使用这个方法做过一个匿名投票,投票的主题是“冷战期间,如果苏联要摧毁美国的主要工业目标,需要多少枚原子弹?”。
他们找来了一群专家,包括4名经济学家、1名物理脆弱性方面的专家、1名系统分析师及1名电气工程师。这几个人都是各个领域的专家,但是第一轮投票的结果差别非常大,少则50枚,多则5000枚。
在第一轮投票后,组织方将各个专家的意见整合后发给了大家,比如各个目标的脆弱性、各个行业的恢复能力、工厂的安全性、不同零部件的交付周期、打击目标的准确性等等,然后又组织各位专家进行了第二次投票,评估差异缩小到了89~800之间。
反复开展上述过程,最终差异越来越小,最后落在了167~360之间。
最初的评估结果相差100倍,到最后,缩小到了2倍。借助这一工具,既能让专家达成普遍的共识,又不会担心出现什么偏见。

5. 如何估算故事点
5.1. 确定基准故事点
每次估算时,最好使用相同的基准用户故事作为1个点(称作 基准故事点,类似表示距离时先确定好1km代表多长),这样对于整个项目的统计有很大帮助。其他的故事都基于这个基准故事做相对估算,就可以得到其他故事的工作量了,每个迭代完成的故事点可以有效的统计团队生产能力在各个迭代的变化。
5.2. 相对估算的依据
基准故事点确定好以后,其他的故事怎样与它对比呢?怎样确定另一个故事的工作量是基准故事的几倍呢?我们可以从以下3个因素考虑:- 要开展的工作数量(The Amount of Work)
如果要开展的工作越多,工作量的估算值当然就会越大。考虑两个网页开发的案例。第一个网页只有一个字段和一个要求输入姓名的标签。第二个网页有100个要输入一小段文本的字段。
第二个网页并不比第一个网友更复杂。字段之间是不存在交互的,每个字段只不过是一点文本而已。因此第二个网页并不存在额外的风险。这两网页之间的唯一区别就是第二页有更多的事情要做。
- 风险和不确定性(Risk and Uncertainty)
用户故事的风险和不确定性会影响其故事点估算值。

如果用户故事的干系人在询问需求时说得不清不楚,那么团队在估算时应当把不确定性也反映在估算结果中。
- 复杂度(Complexity)
在进行故事点估算时,还应该考虑复杂度。回顾一下之前那个有100个琐碎文本字段且字段之间无交互的Web网页开发的例子。
现在考虑另一个也有100个字段的网页。但这些字段中,有些是采用日历控件弹出的日期字段;有些是格式化的文本字段,如电话号码或身份证号;另一些字段则需要做银行卡号的校验和验证。
页面上的字段之间还要相互交互。如果用户输入的是一个189开头的号码,则运营商字段默认显示中国电信。但是如果用户输入的是一个139开头的号码,则运营商字段默认显示中国移动。
尽管这个页面上仍然只有100个字段,但这些字段更难实现。它们更复杂,需要花更多时间才能实现。开发人员出错的可能性更大,因此不得不采取一些预防和纠正措施。
5.3. 使用规划扑克集体估点

- 如果有人出了“☕️”这个扑克,说明需要休息一会了;
- 如果有人出了“?”这个扑克,说明他不了解需求,无法估算工作量,PO需要尝试重新澄清需求。
同4.2节介绍的案例一样,我们在规划故事点数时,第一轮大家的估点可能也会有很大的差距。如果估算值差距明显,代表大家对该用户故事的工作量、风险和不确定性、复杂度没有达成共识,估点高和估点低的人需要给他们一个机会阐述如此估点的理由。大家对该故事所包含的细节达成共识后,再对故事点数进行重新评估,直至大家对故事点数的评估基本达成一致。
如果对于同一个用户故事,估算的故事点数可能不完全一致,但点数之间差距不大,比如在3和5个故事点之间,该用户故事的故事点可以采用平均值法进行计算,计算方法是将估点的平均值与斐波那契数列相比较,并把与平均值差值较小的故事点作为用户故事的最终点数。
参考资料:
- 《敏捷革命》,Jeff Sutherland,中信出版集团。
- Why the fibonacci sequence works well for estimating,Mike Cohn。
- The main benefit of story points,Mike Cohn。
- What are story points,Mike Cohn。
- 韦伯定律,百度百科。
- 黄金比例分割,百度百科。
- 斐波那契数列,百度百科。
- 德尔菲法,百度百科。
- How to Estimate Story Points With Multiple Teams,Mike Cohn。

- 联系人:阿道
- 联系方式: 17762006160
- 地址:青岛市黄岛区长江西路118号青铁广场18楼
如果您有优秀的原创文章,欢迎添加联系人直接与我们联系,或通过下方邮箱发送投稿文章,一经采用,我们会付以一定的稿件报酬。
- 投稿邮箱: yanruiyu@easycorp.ltd
- 投稿标题:向 [敏捷开发] 网站投稿
- 稿件要求:与敏捷开发相关的任何内容
更多投稿相关请点击 更多进行了解~

